Home
Product
Overview
Architecture
Low Latency
INGESTION
Mixed workloads
elasticity
SECURITY
CASE STUDIES
Is Firebolt right for Me
Knowledge Center
INTEGRATIONS
docs
pricing
RESOURCES
company
Contact US
HANDS-ON WORKSHOP
Firebolt was architected from the ground up to leverage the benefits of the cloud, so you can build robust and scalable analytics experiences that will last.
Firebolt is a columnar Data Warehouse built for low-latency analytics workloads at TB++ scale with built-in storage optimization. As a SaaS offering, there are no server or software upgrades to manage, lowering operational overhead and costs.


The promise of endless compute and unlimited storage in the cloud sounds great. But when delivering fast analytics, this could require huge clusters with expensive block storage and it becomes unaffordable for most. Firebolt is not just fast, but also introduces new levels of hardware efficiency. This means that you can deliver sub-second TB++ scale analytics using small and affordable compute clusters.
Firebolt’s decoupled storage and compute architecture allows you to easily scale as your data challenges grow, without the traditional complexities. Firebolt’s unique “F3” file format is optimized for sub-second performance while reducing capacity and cost through the use of columnar compression on object storage. Additionally, granular compute and scale-up/scale-out/scale-in/scale-to-zero of Firebolt engines provides the ultimate control in data warehouse infrastructure provisioning.
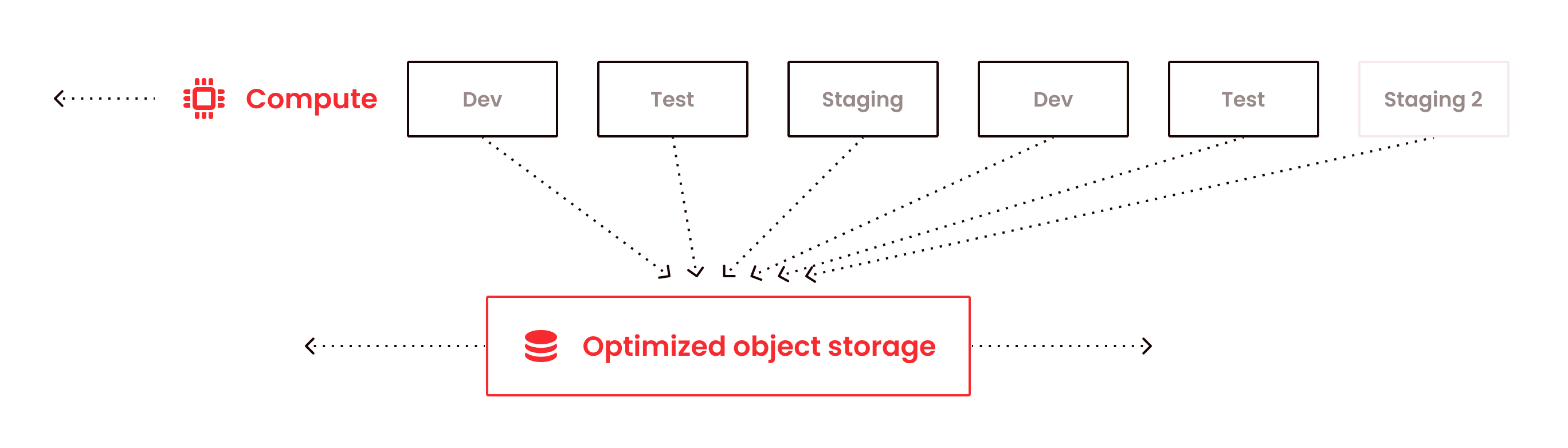
With decoupled storage and compute, Firebolt makes it easy to spin up dev/test environments or scale your production workloads, all the while maintaining workload and resource isolation. Accessing data or Ingesting data from object storage is as simple as “insert into table select * from object_storage”.
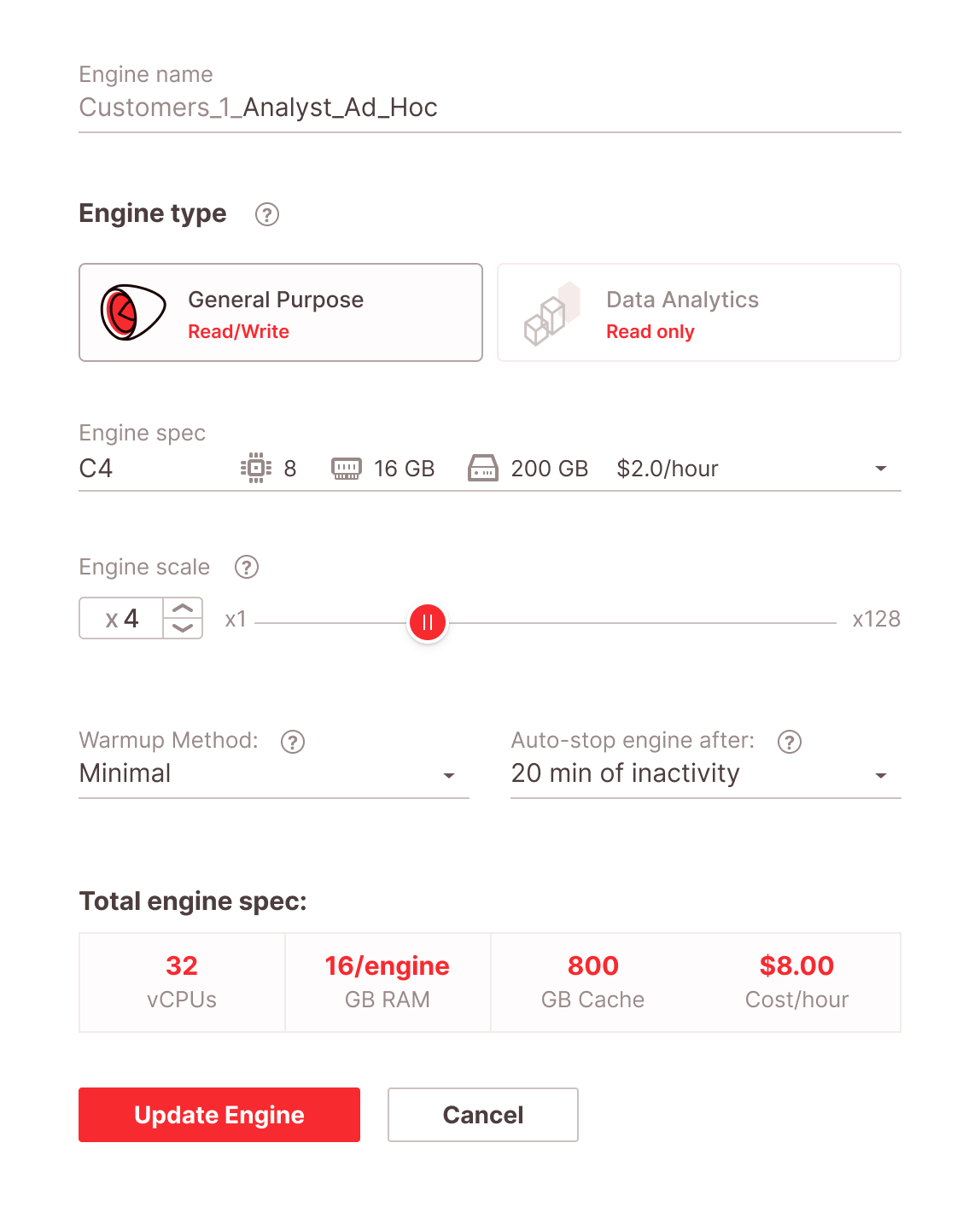
At Firebolt, we believe that modern data engineering & dev teams value the ability to control what they’re running. This is why Firebolt lets you be very granular in your compute resource choices, letting you choose different CPU, SSD, and RAM combinations. This will allow you to optimize your resources for the best price-performance ratio, without over-spending on under-utilized resources. Performance optimization gets the most out of your object storage with no additional uplift. Firebolt’s pricing model is simple, transparent without any tier uplifts.
Firebolt Query optimizer parses each query, builds a logical query plan, and then applies plan transformations and rewrites to derive the best physical query plan. Firebolt’s use of sparse indexing combined with F3 file format reduces the amount of data fetched over the network by over 10X or more enabling sub-second analytics.
Further, the query optimizer evaluates whether query performance can be improved by reordering query operations, or by using indexes in place of operations, reordering operations to take advantage of predicate pushdowns, and uses aggregating and join indexes to further reduce both data access and scans. This helps reduce data sets before accessing data or performing joins boosting performance with both star and snowflake schemas.
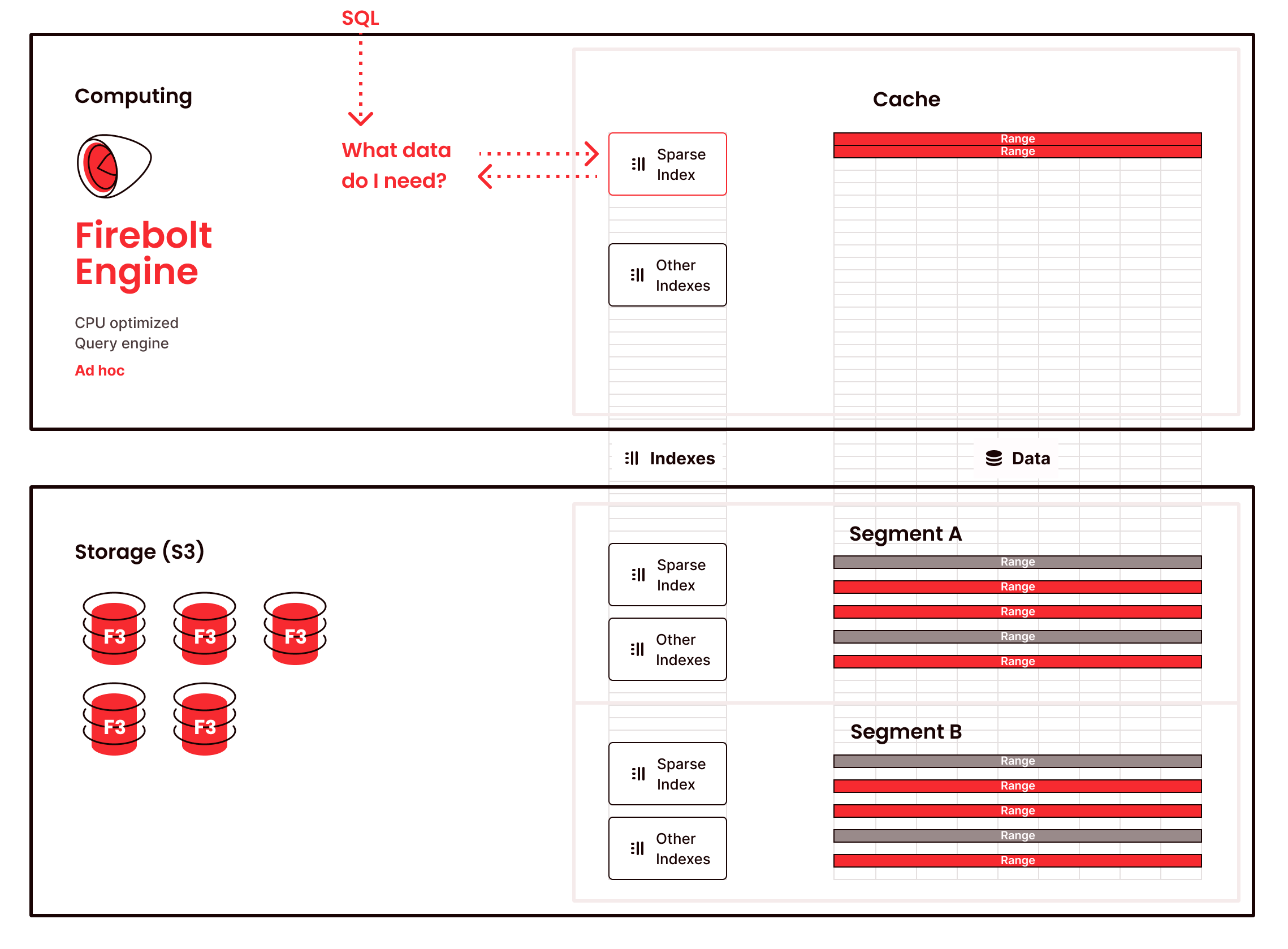
Firebolt uses indexing extensively to improve performance. Each table has a sparse (primary) index consisting of any number of columns in any order. In addition, there are indexes that help with aggregations or joins. Indexes dramatically improve performance and overcome some of the limitations of decoupled storage and compute. They are also updated and optimized during ingestion eliminating the need for additional management.
This optimization of storage and compute with indexing reduces both remote data access and the amount of data cached by 10x or more, which also leads to 10x less data to scan and process.

Firebolt speaks ANSI-SQL, and sports a SQL IDE that you’ll actually enjoy using. We won’t discourage you from using joins and won’t encourage you to denormalize your data - it’s easy to remain fast with Firebolt.
Additionally, Firebolt partners with modern data stack solutions that harness Firebolt’s speed, scale and efficiency to extend what customers can achieve using complementary integrations and capabilities.

Results below illustrate Firebolt performance gains with smaller and cheaper clusters Vs Snowflake customer. Actual customer results with a 0.5TB dataset.



Provides sub-second latency at TB++ scale and enables high concurrency workloads

Leverages Cloud Elasticity and Scale while providing granular provisioning.

Data warehouse data is stored separately from compute. This enables spinning up multiple compute engines to process the data. For example, two competing workloads can be run on separate engines while accessing the same data on optimized object storage.

Indexes enable effective pruning of data for access, joins and aggregations. Index maintenance is abstracted away from the administrator.

Software as a Service eliminates server, software maintenance. Customers can focus on bringing and using their data immediately, reducing time to value significantly.

Simplified pricing based on compute and object storage consumption. No tier upgrades or unpredictable add-ons.

Firebolt extends its functionality through ecosystem partners such as Airflow, DBT, Tableau, Looker and others.

Firebolt leverages ANSI-SQL to support SQL functionality.
