Home
Product
Overview
Architecture
Low Latency
INGESTION
Mixed workloads
elasticity
SECURITY
CASE STUDIES
Is Firebolt right for Me
Knowledge Center
INTEGRATIONS
docs
pricing
RESOURCES
company
Contact US
HANDS-ON WORKSHOP
Firebolt is a columnar Data Warehouse built for low-latency analytics workloads at TB++ scale with built-in storage optimization. As a SaaS offering, there are no server or software upgrades to manage, lowering operational overhead and costs.

Firebolt’s decoupled storage and compute architecture allows you to easily scale as your data challenges grow, without the traditional complexities. Firebolt’s unique “F3” file format is optimized for sub-second performance while reducing capacity and cost through the use of columnar compression on object storage. Additionally, granular compute and scale-up/scale-out/scale-in/scale-to-zero of Firebolt engines provides the ultimate control in data warehouse infrastructure provisioning.
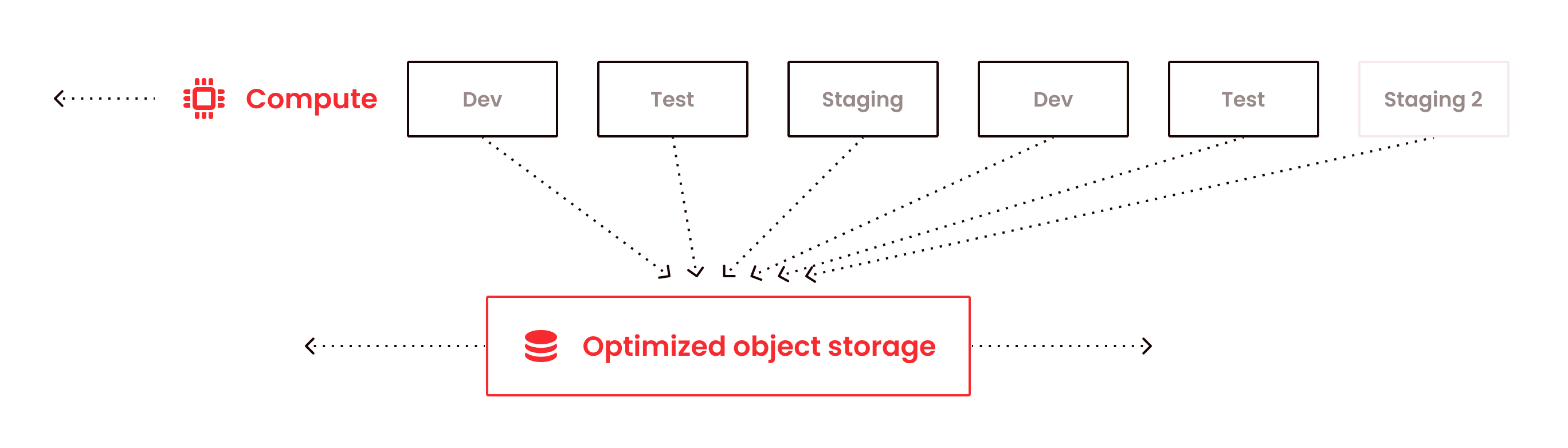
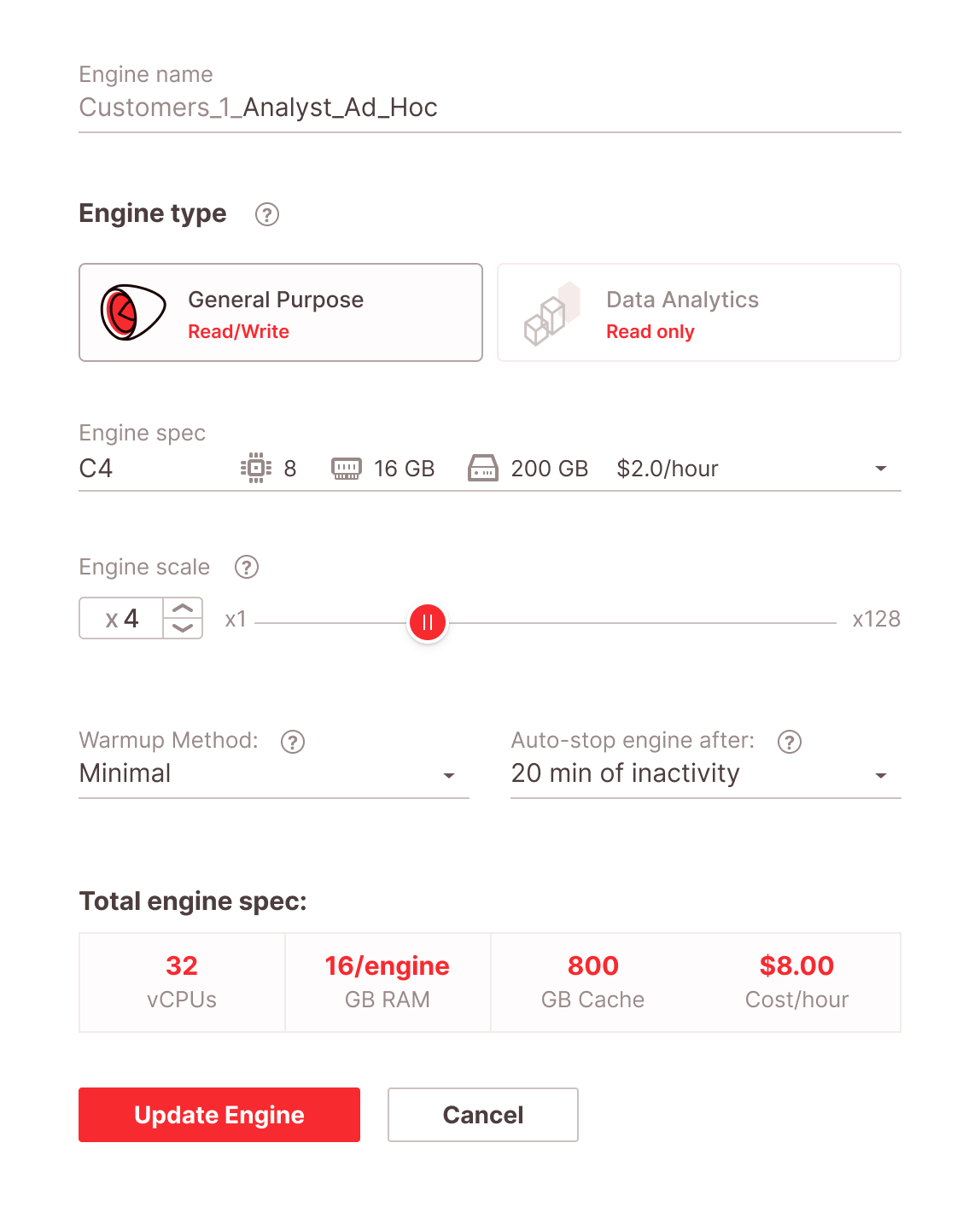
At Firebolt, we believe that modern data engineering & dev teams value the ability to control what they’re running. This is why Firebolt lets you be very granular in your compute resource choices, letting you choose different CPU, SSD, and RAM combinations. This will allow you to optimize your resources for the best price-performance ratio, without over-spending on under-utilized resources. Performance optimization gets the most out of your object storage with no additional uplift. Firebolt’s pricing model is simple, transparent without any tier uplifts.
Firebolt uses indexing extensively to improve performance. Each table has a sparse (primary) index consisting of any number of columns in any order. In addition, there are indexes that help with aggregations or joins. Indexes dramatically improve performance and overcome some of the limitations of decoupled storage and compute. They are also updated and optimized during ingestion eliminating the need for additional management.
This optimization of storage and compute with indexing reduces both remote data access and the amount of data cached by 10x or more, which also leads to 10x less data to scan and process.


